The Interface Between Reinforcement Learning Theory and Language Model Post-Training
We have another technical blog post, this time by Akshay Krishnamurthy and Audrey Huang, about how ideas from reinforcement learning theory can inspire new algorithms for language model post-training.
Over the last several years, we have seen an explosion of interest and research activity into generative models—particularly large language models like ChatGPT, Claude, and Gemini—which operate via textual inputs and outputs and can be used for a variety of general-purpose tasks like question-answering, creative writing, and reasoning. At a high level, training these models comprises two phases: (1) in the pre-training phase, the model is trained on a large corpus of text to predict each token (word) given the previous tokens in each document, (2) in the post-training phase, a variety of techniques are deployed to align the model, making it suitable for downstream use. For instance, alignment techniques are used to control or steer the model away from producing inappropriate or offensive content, which is essential for safe deployment.
One of the standard approaches for language model alignment is known as Reinforcement Learning from Human Feedback (RLHF). The idea is to treat the language model as a decision-making policy and use techniques from reinforcement learning (RL) to optimize for desirable outcomes, where the notion of desirability is derived from a dataset of outcomes curated with human feedback. These RLHF approaches are pervasive; they are employed in the training of essentially every language model. This new application of RL presented an exciting opportunity for the RL research community to translate, refine, and deploy their ideas toward improving language model alignment, and progress in this direction has been rather rapid. In this blog post, we will discuss some recent advances—focusing on theoretical developments—in reinforcement learning for language model alignment.
As an outline, most of this blog post will focus on the most standard setting for RLHF. We will start with some background to set the stage, highlight the central challenge of overoptimization, and then present a new algorithm, chi-squared preference optimization, that we (in joint work with Wenhao Zhan, Tengyang Xie, Jason Lee, Wen Sun, and Dylan Foster) developed to mitigate this issue. To wrap up, we’ll briefly highlight some other work at the interface of RL theory and LLM post-training, and close with some parting thoughts.
Background
The most basic formulation of RLHF considers single-turn chat scenarios where there is a space 






- Prompts
are drawn from some prompt distribution
,
- Two responses
are drawn independently from
,
- These responses are ordered as
based on the Bradley-Terry model parametrized by an unknown reward function
:
![\displaystyle \Pr[y \succ y'] = \frac{\exp(r^\star(x,y))}{\exp(r^\star(x,y)) + \exp(r^\star(x,y'))}](https://s0.wp.com/latex.php?latex=%5Cdisplaystyle+%5CPr%5By+%5Csucc+y%27%5D+%3D+%5Cfrac%7B%5Cexp%28r%5E%5Cstar%28x%2Cy%29%29%7D%7B%5Cexp%28r%5E%5Cstar%28x%2Cy%29%29+%2B+%5Cexp%28r%5E%5Cstar%28x%2Cy%27%29%29%7D&bg=ffffff&fg=000&s=0&c=20201002)
Given this dataset, we aim to learn a policy that has high reward ![\arg\max_{\pi} \mathbb{E}_{x\sim D_x, y \sim \pi(\cdot\mid x)}[ r^\star(x,y) ]](https://s0.wp.com/latex.php?latex=%5Carg%5Cmax_%7B%5Cpi%7D+%5Cmathbb%7BE%7D_%7Bx%5Csim+D_x%2C+y+%5Csim+%5Cpi%28%5Ccdot%5Cmid+x%29%7D%5B+r%5E%5Cstar%28x%2Cy%29+%5D&bg=ffffff&fg=000&s=0&c=20201002)
A natural approach, first proposed by Christiano et al (2017), is to use the preference dataset 
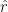
![\displaystyle \hat{\pi}_{\mathrm{RLHF}} = \mathrm{argmax}_{\pi} \mathbb{E}_{x\sim D_x, y \sim \pi(\cdot\mid x)}[ \hat{r}(x,y) ] - \beta D_{\mathrm{KL}}(\pi || \pi_{\mathrm{ref}} )](https://s0.wp.com/latex.php?latex=%5Cdisplaystyle+%5Chat%7B%5Cpi%7D_%7B%5Cmathrm%7BRLHF%7D%7D+%3D+%5Cmathrm%7Bargmax%7D_%7B%5Cpi%7D+%5Cmathbb%7BE%7D_%7Bx%5Csim+D_x%2C+y+%5Csim+%5Cpi%28%5Ccdot%5Cmid+x%29%7D%5B+%5Chat%7Br%7D%28x%2Cy%29+%5D+-+%5Cbeta+D_%7B%5Cmathrm%7BKL%7D%7D%28%5Cpi+%7C%7C+%5Cpi_%7B%5Cmathrm%7Bref%7D%7D+%29&bg=ffffff&fg=000&s=0&c=20201002)
Where ![D_{\mathrm{KL}}(\pi || \pi_{\mathrm{ref}} ) = \mathbb{E}_{x \sim D_x}[ D_{\mathrm{KL}}(\pi(\cdot \mid x) || \pi_{\mathrm{ref}}(\cdot \mid x) ]](https://s0.wp.com/latex.php?latex=D_%7B%5Cmathrm%7BKL%7D%7D%28%5Cpi+%7C%7C+%5Cpi_%7B%5Cmathrm%7Bref%7D%7D+%29+%3D+%5Cmathbb%7BE%7D_%7Bx+%5Csim+D_x%7D%5B+D_%7B%5Cmathrm%7BKL%7D%7D%28%5Cpi%28%5Ccdot+%5Cmid+x%29+%7C%7C+%5Cpi_%7B%5Cmathrm%7Bref%7D%7D%28%5Ccdot+%5Cmid+x%29+%5D&bg=ffffff&fg=000&s=0&c=20201002)
One issue with this approach is that, by using reinforcement learning for optimization, it inherits the brittleness and instability of deep reinforcement learning. To address this, Rafailov et al (2023), observed a certain duality between policies and rewards and used it to derive a much simpler method, called Direct Preference Optimization (DPO). The idea is that for any reward function 

where 


Unfortunately, both standard RLHF and DPO have been observed to suffer from a phenomenon referred to as overoptimization (e.g., in Gao et al (2023)), where the policy degrades in quality, rather than improves, during the optimization process. As we will see in the next section, one explanation for overoptimization is that it arises from a certain statistical inefficiency of both methods, which can be addressed via a novel algorithm design.
Overoptimization hurts performance in RLHF
Overoptimization can be understood by connecting the RLHF setting to a subfield of reinforcement learning theory known as offline reinforcement learning. Although RL typically concerns an agent interacting with an environment in an online manner, it can be more practical/feasible to learn in an offline manner, from data that was previously collected by some other decision-making policy (this is also a useful subroutine in online methods). Since we are unable to interact with the environment in these settings and the dataset may not contain information/demonstrations of near-optimal behavior, a natural desideratum is to do the best we can with the data that we have, i.e., find a policy whose performance is competitive with the best policy “supported” by the data. Recent developments in the theory of offline RL have formalized such guarantees via a notion of “single-policy concentrability” (whose definition is not essential for understanding this blog post).
The fundamental challenge in offline RL is a mismatch between what we can numerically optimize—i.e., an estimate of policy performance based on the data we have—and what we care to optimize—the actual policy performance—resulting in an instance of Goodhardt’s Law. To see this in more detail, observe that the RLHF setting described above is a special case of offline RL because the dataset is collected a priori by 

To address the overfitting challenge (and achieve guarantees based on single policy concentrability), the offline RL literature has developed algorithms based on the principle of pessimism—which quantify reward uncertainty and maximize a high confidence lower bound on reward (thus guaranteeing a certain amount of reward). Pessimism can be seen as a form of regularization which forces the optimization process to stay in the region where 
Deep dive into Chi-squared preference optimization
Although regularization with KL-divergence is insufficient, it turns out that regularization with the 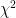
![D_{\chi^2}(\pi || \pi_{\mathrm{ref}}) = \frac{1}{2} \mathbb{E}_{x \sim D_x,y \sim \pi_{\mathrm{ref}}(\cdot \mid{} x)}[ (\pi(y|x)/\pi_{\mathrm{ref}}(y|x) - 1)^2]](https://s0.wp.com/latex.php?latex=D_%7B%5Cchi%5E2%7D%28%5Cpi+%7C%7C+%5Cpi_%7B%5Cmathrm%7Bref%7D%7D%29+%3D+%5Cfrac%7B1%7D%7B2%7D+%5Cmathbb%7BE%7D_%7Bx+%5Csim+D_x%2Cy+%5Csim+%5Cpi_%7B%5Cmathrm%7Bref%7D%7D%28%5Ccdot+%5Cmid%7B%7D+x%29%7D%5B+%28%5Cpi%28y%7Cx%29%2F%5Cpi_%7B%5Cmathrm%7Bref%7D%7D%28y%7Cx%29+-+1%29%5E2%5D&bg=ffffff&fg=000&s=0&c=20201002)







We can expect to have low in-distribution risk, say, ![\mathbb{E}_{x \sim D_x, y \sim \pi_{\mathrm{ref}}(\cdot \mid x)}[ (\hat{r}(x,y) - r^\star(x,y))^2] \leq \varepsilon^2_{\mathrm{stat}}](https://s0.wp.com/latex.php?latex=%5Cmathbb%7BE%7D_%7Bx+%5Csim+D_x%2C+y+%5Csim+%5Cpi_%7B%5Cmathrm%7Bref%7D%7D%28%5Ccdot+%5Cmid+x%29%7D%5B+%28%5Chat%7Br%7D%28x%2Cy%29+-+r%5E%5Cstar%28x%2Cy%29%29%5E2%5D+%5Cleq+%5Cvarepsilon%5E2_%7B%5Cmathrm%7Bstat%7D%7D&bg=ffffff&fg=000&s=0&c=20201002)
![\mathbb{E}_\pi[r^\star(x,y)]](https://s0.wp.com/latex.php?latex=%5Cmathbb%7BE%7D_%5Cpi%5Br%5E%5Cstar%28x%2Cy%29%5D&bg=ffffff&fg=000&s=0&c=20201002)
![\mathbb{E}_{\pi}[\hat{r}(x,y)]](https://s0.wp.com/latex.php?latex=%5Cmathbb%7BE%7D_%7B%5Cpi%7D%5B%5Chat%7Br%7D%28x%2Cy%29%5D&bg=ffffff&fg=000&s=0&c=20201002)
![\displaystyle \mathbb{E}_\pi[ r^\star(x,y) - \hat{r}(x,y) ] \\= \mathbb{E}_x\left[ \sum_y \frac{\pi(y\mid{}x)}{\sqrt{\pi_{\mathrm{ref}}(y \mid{}x)}}\cdot\sqrt{\pi_{\mathrm{ref}}(y \mid{}x)} \cdot (r^\star(x,y) - \hat{r}(x,y) )\right]\\ \leq \sqrt{ \mathbb{E}_x\left[\sum_y \frac{\pi^2(y\mid{}x)}{\pi_{\mathrm{ref}}(y \mid{}x)}\right]}\cdot\varepsilon_{\mathrm{stat}}\\ = \sqrt{ \mathbb{E}_{\pi_{\mathrm{ref}}} \left[ \frac{\pi^2(y\mid{}x)}{\pi^2_{\mathrm{ref}}(y\mid{}x)} \right]} \cdot \varepsilon_{\mathrm{stat}}\\ = \sqrt{2D_{\chi^2}(\pi ||\pi_{\mathrm{ref}}) + 1} \cdot \varepsilon_{\mathrm{stat}}](https://s0.wp.com/latex.php?latex=%5Cdisplaystyle+%5Cmathbb%7BE%7D_%5Cpi%5B+r%5E%5Cstar%28x%2Cy%29+-+%5Chat%7Br%7D%28x%2Cy%29+%5D+%5C%5C%3D+%5Cmathbb%7BE%7D_x%5Cleft%5B+%5Csum_y+%5Cfrac%7B%5Cpi%28y%5Cmid%7B%7Dx%29%7D%7B%5Csqrt%7B%5Cpi_%7B%5Cmathrm%7Bref%7D%7D%28y+%5Cmid%7B%7Dx%29%7D%7D%5Ccdot%5Csqrt%7B%5Cpi_%7B%5Cmathrm%7Bref%7D%7D%28y+%5Cmid%7B%7Dx%29%7D+%5Ccdot+%28r%5E%5Cstar%28x%2Cy%29+-+%5Chat%7Br%7D%28x%2Cy%29+%29%5Cright%5D%5C%5C++%5Cleq+%5Csqrt%7B+%5Cmathbb%7BE%7D_x%5Cleft%5B%5Csum_y+%5Cfrac%7B%5Cpi%5E2%28y%5Cmid%7B%7Dx%29%7D%7B%5Cpi_%7B%5Cmathrm%7Bref%7D%7D%28y+%5Cmid%7B%7Dx%29%7D%5Cright%5D%7D%5Ccdot%5Cvarepsilon_%7B%5Cmathrm%7Bstat%7D%7D%5C%5C+%3D+%5Csqrt%7B+%5Cmathbb%7BE%7D_%7B%5Cpi_%7B%5Cmathrm%7Bref%7D%7D%7D+%5Cleft%5B+%5Cfrac%7B%5Cpi%5E2%28y%5Cmid%7B%7Dx%29%7D%7B%5Cpi%5E2_%7B%5Cmathrm%7Bref%7D%7D%28y%5Cmid%7B%7Dx%29%7D+%5Cright%5D%7D+%5Ccdot+%5Cvarepsilon_%7B%5Cmathrm%7Bstat%7D%7D%5C%5C+%3D+%5Csqrt%7B2D_%7B%5Cchi%5E2%7D%28%5Cpi+%7C%7C%5Cpi_%7B%5Cmathrm%7Bref%7D%7D%29+%2B+1%7D+%5Ccdot+%5Cvarepsilon_%7B%5Cmathrm%7Bstat%7D%7D+&bg=ffffff&fg=000&s=0&c=20201002)
In other words, the
![\displaystyle \hat{\pi}_{\mathrm{RLHF}} = \mathrm{argmax}_{\pi} \mathbb{E}_{x\sim D_x, y \sim \pi(\cdot\mid x)}[ \hat{r}(x,y) ] - \beta D_{\chi^2}(\pi || \pi_{\mathrm{ref}} )](https://s0.wp.com/latex.php?latex=%5Cdisplaystyle+%5Chat%7B%5Cpi%7D_%7B%5Cmathrm%7BRLHF%7D%7D+%3D+%5Cmathrm%7Bargmax%7D_%7B%5Cpi%7D+%5Cmathbb%7BE%7D_%7Bx%5Csim+D_x%2C+y+%5Csim+%5Cpi%28%5Ccdot%5Cmid+x%29%7D%5B+%5Chat%7Br%7D%28x%2Cy%29+%5D+-+%5Cbeta+D_%7B%5Cchi%5E2%7D%28%5Cpi+%7C%7C+%5Cpi_%7B%5Cmathrm%7Bref%7D%7D+%29+&bg=ffffff&fg=000&s=0&c=20201002)
and appropriately tuning 
Based on this observation, the main contribution of the paper is a “direct” variant of 

As a final note, we have run preliminary experiments with

At the same time, the fact that we do not observe large performance gains indicates that statistical overfitting is not the whole story, and suggests many avenues for further investigation. For a theoretical audience, perhaps the most interesting of these are (a) the way preference data is collected in standard benchmarks does not precisely conform to our mathematical setup (in particular it is not clear that the responses are sampled from
Parting thoughts
As we mentioned in the introduction, the interface between RL theory and LLMs is a very active research area. Directly relevant to
To summarize, we believe there is tremendous potential for a diversity of theoretical perspectives to have an impact in language model post-training and generative AI more broadly. New formalizations and connections with other areas can lead to deeper understanding and novel algorithmic interventions. At the same time, clean mathematical testbeds, while useful, are unlikely to capture the full complexity of modern generative AI. As we’ve learned through our experience working on