Structure-Agnostic Causal Estimation
We have another new technical blog post, courtesy Jikai Jin and Vasilis Syrgkanis, about optimality of double machine learning for causal inference.
An introduction to causal inference
Causal inference deals with the fundamental question of “what if”, trying to estimate/predict the counterfactual outcome that one does not directly observe. For instance, one may want to understand the effect of a new medicine on a population of patients. For each patient, we never simultaneously observe the outcome under the new medicine (treatment) and the outcome under the baseline treatment (control). This makes causal inference a challenging task, and the ground-truth causal parameter of interest is identifiable only under additional assumptions on the data generating process.
The most central quantity of interest in the causal inference literature is the Average Treatment Effect (ATE). To mathematically define the ATE, we will use the language of potential outcomes. We posit that nature generates two potential outcomes 



![\theta = \mathbb{E}_{P_0}[Y(1)-Y(0)]](https://s0.wp.com/latex.php?latex=%5Ctheta+%3D+%5Cmathbb%7BE%7D_%7BP_0%7D%5BY%281%29-Y%280%29%5D&bg=ffffff&fg=000&s=0&c=20201002)
Unless otherwise specified, we will always use a subscript 

The first key question in causal inference is the identification question: can we write the ATE, which depends on the distribution of unobserved quantities, as a function of the distribution of observed random variables? Many techniques have been developed in causal inference that solve the identification question under various assumptions on the data generating process and the kinds of variables that are observed. For the interested reader, one can search for terms such as identification by conditioning, instrumental variables, proximal causal inference, difference-in-differences, regression discontinuity and synthetic controls, and refer to related textbooks [AP09,CHK+24].
For the purpose of this blog we will focus on identification by conditioning, which has been well-studied in the literature and very frequently used in the practice of causal inference. This identification approach makes the assumption that, once we condition on a large enough set of observed characteristics 

Under this assumption, the ATE is identifiable via the well-known g-formula:
![\theta = \mathbb{E}[g(1,X)-g(0,X)]](https://s0.wp.com/latex.php?latex=%5Ctheta+%3D+%5Cmathbb%7BE%7D%5Bg%281%2CX%29-g%280%2CX%29%5D&bg=ffffff&fg=000&s=0&c=20201002)
where the function ![g(d,x) = \mathbb{E}[Y\mid X=x, D=d]](https://s0.wp.com/latex.php?latex=g%28d%2Cx%29+%3D+%5Cmathbb%7BE%7D%5BY%5Cmid+X%3Dx%2C+D%3Dd%5D&bg=ffffff&fg=000&s=0&c=20201002)
The causal machine learning paradigm
The second key question in causal inference is the estimation question: given 


At a high level, causal machine learning is an emerging research area that incorporates machine learning (ML) techniques into statistical problems that emerge in causal inference. In the past decade, ML has gained tremendous success on numerous tasks, such as image classification, language processing, and video games. These problems more or less possess certain intrinsic structures that one can exploit. In image classification problems, for example, semantically meaningful objects can typically be found locally as a combination of pixels, and this suggests that using convolutional neural networks, rather than standard feed-forward neural networks, might lead to better results. The idea of causal machine learning is to leverage the ability of ML techniques to adapt to intrinsic notions of dimension, when learning the complex nuisance quantities that arise in causal identification strategies.
Double/debiased machine learning: an overview
What makes causal ML different from ML? To answer this question, it is instructive to revisit an extremely popular algorithm in causal ML: double/debiased machine learning (DML)[CCD+17] (variants of the ideas we will present below have also appeared in the targeted learning literature [LR11], but for simplicity of exposition we adopt the DML paradigm in this blogpost).
Suppose that we are given i.i.d. data 
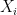
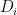
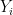
![Y = g(D,X) + \epsilon, \quad \mathbb{E}[\epsilon\mid D,X]=0](https://s0.wp.com/latex.php?latex=Y+%3D+g%28D%2CX%29+%2B+%5Cepsilon%2C+%5Cquad+%5Cmathbb%7BE%7D%5B%5Cepsilon%5Cmid+D%2CX%5D%3D0&bg=ffffff&fg=000&s=0&c=20201002)
![D=p(X)+\eta, \quad \mathbb{E}[\eta \mid X]=0](https://s0.wp.com/latex.php?latex=D%3Dp%28X%29%2B%5Ceta%2C+%5Cquad+%5Cmathbb%7BE%7D%5B%5Ceta+%5Cmid+X%5D%3D0&bg=ffffff&fg=000&s=0&c=20201002)
where 
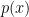
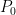

![\theta_0 = E[g(1,X) - g(0,X)]](https://s0.wp.com/latex.php?latex=%5Ctheta_0+%3D+E%5Bg%281%2CX%29+-+g%280%2CX%29%5D&bg=ffffff&fg=000&s=0&c=20201002)
The ATE is just one example of a broad class of causal parameter estimation problems, for which the ground-truth parameter 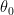
![\mathbb{E}[m(Z,\theta_0,h_0(X))]=0](https://s0.wp.com/latex.php?latex=%5Cmathbb%7BE%7D%5Bm%28Z%2C%5Ctheta_0%2Ch_0%28X%29%29%5D%3D0&bg=ffffff&fg=000&s=0&c=20201002)
where 
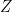
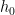





However, the resulting estimate 
The key observation is that this would be the case if a Neyman orthogonality condition holds, namely
![\mathbb{E}\left[\partial_h m\left(Z, \theta_0, h_0(X)\right)\right]=0](https://s0.wp.com/latex.php?latex=%5Cmathbb%7BE%7D%5Cleft%5B%5Cpartial_h+m%5Cleft%28Z%2C+%5Ctheta_0%2C+h_0%28X%29%5Cright%29%5Cright%5D%3D0&bg=ffffff&fg=000&s=0&c=20201002)
where 

Intuitively, this condition implies that the induced error is less sensitive to misspecification of nuisance function. Then a simple Taylor expansion would imply that the estimation error 
In the case of ATE, the moment function

satisfies such requirements, where 



- Use our favorite ML method (e.g. Lasso, random forest, neural network etc.) to estimate
and
.
- Solve for

where 
Note that the main reason why DML would improve over the naive approach is that the moment function is chosen to satisfy the Neyman orthogonality property. By contrast, one can easily verify that the moment function
It is well-known that for the case of the ATE, the DML approach also possesses double robustness properties; a property that dates back to the seminal work of [RRZ94]. In fact the resulting estimator is the well-known doubly robust estimator [RRZ94] with the extra element of sample splitting, when estimating the nuisance functions. Specifically, suppose that our first-stage nuisance estimates have mean-square errors 


with high probability. Intuitively, because the estimation error of 
![\mathbb{E}\left[\partial_g^{\alpha}\partial_p^{\beta} m\left(Z, \theta_0, h_0(X)\right)\right]\neq 0](https://s0.wp.com/latex.php?latex=%5Cmathbb%7BE%7D%5Cleft%5B%5Cpartial_g%5E%7B%5Calpha%7D%5Cpartial_p%5E%7B%5Cbeta%7D+m%5Cleft%28Z%2C+%5Ctheta_0%2C+h_0%28X%29%5Cright%29%5Cright%5D%5Cneq+0&bg=ffffff&fg=000&s=0&c=20201002)

Importantly, this guarantee is structure-agnostic: this rate does not rely on any structural assumptions on the nuisance functions. What we need to assume is merely access to black-box ML estimates with some mean-squared error bounds. This is the reason why DML is widely adopted in practice: while there exist alternative estimators that can achieve improved error rates under structural assumptions on the non-parametric components, these assumptions can easily be violated, making these estimators cumbersome to deploy.
The problems that causal ML studies are not new. In the non-parametric estimation literature, there have been extensive results that focus on non-parametric efficiency and optimal rates for estimating causal quantities, under structural assumptions on the model such as smoothness of the non-parametric parts of the data generating process [RLM17,KBRW22]. However, the causal ML approach takes a more structure-agnostic view on the estimation of these nuisance quantities, and essentially solely assumes access to a good black-box oracle that provides us with relatively accurate estimates. This naturally gives rise to the structure-agnostic minimax optimality framework.
The structure-agnostic framework
We have seen that the key characteristic that differentiates the causal ML approach to estimation (e.g. the DML approach) with the traditional approaches is its structure-agnostic nature. In this section, we discuss the structure-agnostic framework that allows us to compare the performance of structure-agnostic estimators. This framework was originally proposed by [BKW23].
To keep things simple, we restrict ourselves to the same setting as the previous section. Now suppose we have nuisance estimates
To formalize this, we define the uncertainty set, as the set containing all distributions that are consistent with the given estimators:


where 



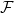


where 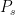





Main results
In this section, we introduce our main results on structure-agnostic lower bounds [JS24]. Prior to our work, the only known structure agnostic lower bounds were established in [BKW23]. In their paper, it is shown that DML is optimal for estimating a set of functionals of interest, which relate to the ATE but which do not include the ATE functional.
Our first result establishes the optimality of DML for estimating the ATE, i.e., the doubly robust estimator with sample splitting, achieves the statistically optimal rate. As discussed in the previous section, the DML estimator for the ATE is given by
![\hat{\theta}^{\mathrm{ATE}}=\frac{1}{n} \sum_{i=1}^n\left[\hat{g}\left(1,X_i\right)-\hat{g}\left(0,X_i\right)+\frac{D_i-\hat{p}\left(X_i\right)}{\hat{p}\left(X_i\right)\left(1-\hat{p}\left(X_i\right)\right)}\left(Y_i-\hat{g}\left(D_i,X_i\right)\right)\right]](https://s0.wp.com/latex.php?latex=%5Chat%7B%5Ctheta%7D%5E%7B%5Cmathrm%7BATE%7D%7D%3D%5Cfrac%7B1%7D%7Bn%7D+%5Csum_%7Bi%3D1%7D%5En%5Cleft%5B%5Chat%7Bg%7D%5Cleft%281%2CX_i%5Cright%29-%5Chat%7Bg%7D%5Cleft%280%2CX_i%5Cright%29%2B%5Cfrac%7BD_i-%5Chat%7Bp%7D%5Cleft%28X_i%5Cright%29%7D%7B%5Chat%7Bp%7D%5Cleft%28X_i%5Cright%29%5Cleft%281-%5Chat%7Bp%7D%5Cleft%28X_i%5Cright%29%5Cright%29%7D%5Cleft%28Y_i-%5Chat%7Bg%7D%5Cleft%28D_i%2CX_i%5Cright%29%5Cright%29%5Cright%5D&bg=ffffff&fg=000&s=0&c=20201002)
and has the structure-agnostic rate of
Theorem 1. Let ![\mathrm{supp}(X)=[0,1]^K](https://s0.wp.com/latex.php?latex=%5Cmathrm%7Bsupp%7D%28X%29%3D%5B0%2C1%5D%5EK&bg=ffffff&fg=000&s=0&c=20201002)




![[c,1-c]](https://s0.wp.com/latex.php?latex=%5Bc%2C1-c%5D&bg=ffffff&fg=000&s=0&c=20201002)


Interestingly, knowing the marginal distribution of
We also consider another important causal parameter, the average treatment effect of the treated (ATT), defined by ![\theta^{ATT}=\mathbb{E}\left[Y(1)-Y(0) \mid D=1\right]](https://s0.wp.com/latex.php?latex=%5Ctheta%5E%7BATT%7D%3D%5Cmathbb%7BE%7D%5Cleft%5BY%281%29-Y%280%29+%5Cmid+D%3D1%5Cright%5D&bg=ffffff&fg=000&s=0&c=20201002)
![\theta^{ATT}=\mathbb{E}\left[Y-g_0(0, X) \mid D=1\right]](https://s0.wp.com/latex.php?latex=%5Ctheta%5E%7BATT%7D%3D%5Cmathbb%7BE%7D%5Cleft%5BY-g_0%280%2C+X%29+%5Cmid+D%3D1%5Cright%5D&bg=ffffff&fg=000&s=0&c=20201002)
The DML estimate of 
![\hat{\theta}_{DML}=\left(\sum_{i=1}^n D_i\right)^{-1}\sum_{i=1}^n\left[D_i\left(Y_i-\hat{g}\left(0,X_i\right)\right)-\frac{\hat{p}\left(X_i\right)}{1-\hat{p}\left(X_i\right)}\left(1-D_i\right)\left(Y_i-\hat{g}\left(0, X_i\right)\right)\right]](https://s0.wp.com/latex.php?latex=%5Chat%7B%5Ctheta%7D_%7BDML%7D%3D%5Cleft%28%5Csum_%7Bi%3D1%7D%5En+D_i%5Cright%29%5E%7B-1%7D%5Csum_%7Bi%3D1%7D%5En%5Cleft%5BD_i%5Cleft%28Y_i-%5Chat%7Bg%7D%5Cleft%280%2CX_i%5Cright%29%5Cright%29-%5Cfrac%7B%5Chat%7Bp%7D%5Cleft%28X_i%5Cright%29%7D%7B1-%5Chat%7Bp%7D%5Cleft%28X_i%5Cright%29%7D%5Cleft%281-D_i%5Cright%29%5Cleft%28Y_i-%5Chat%7Bg%7D%5Cleft%280%2C+X_i%5Cright%29%5Cright%29%5Cright%5D&bg=ffffff&fg=000&s=0&c=20201002)
and can be shown to achieve the same
Theorem 2. In the same setting as Theorem 1, we have

Finally, we can also extend Theorem 1 to the weighted ATE (WATE) defined as
![\theta^{WATE}=\mathbb{E}_{P_0}[w(X)(Y(1)-Y(0))]](https://s0.wp.com/latex.php?latex=%5Ctheta%5E%7BWATE%7D%3D%5Cmathbb%7BE%7D_%7BP_0%7D%5Bw%28X%29%28Y%281%29-Y%280%29%29%5D&bg=ffffff&fg=000&s=0&c=20201002)
which arises in policy evaluation [AW21]. Here 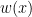
Theorem 3. In the same setting as Theorem 1, we have

where
![\hat{\theta}^{\mathrm{WATE}}=\frac{1}{n} \sum_{i=1}^n w\left(X_i\right)\left[\hat{g}\left(1, X_i\right)-\hat{g}\left(0,X_i\right)+\frac{D_i-\hat{p}\left(X_i\right)}{\hat{p}\left(X_i\right)\left(1-\hat{p}\left(X_i\right)\right)}\left(Y_i-\hat{g}\left(D_i, X_i\right)\right)\right] .](https://s0.wp.com/latex.php?latex=%5Chat%7B%5Ctheta%7D%5E%7B%5Cmathrm%7BWATE%7D%7D%3D%5Cfrac%7B1%7D%7Bn%7D+%5Csum_%7Bi%3D1%7D%5En+w%5Cleft%28X_i%5Cright%29%5Cleft%5B%5Chat%7Bg%7D%5Cleft%281%2C+X_i%5Cright%29-%5Chat%7Bg%7D%5Cleft%280%2CX_i%5Cright%29%2B%5Cfrac%7BD_i-%5Chat%7Bp%7D%5Cleft%28X_i%5Cright%29%7D%7B%5Chat%7Bp%7D%5Cleft%28X_i%5Cright%29%5Cleft%281-%5Chat%7Bp%7D%5Cleft%28X_i%5Cright%29%5Cright%29%7D%5Cleft%28Y_i-%5Chat%7Bg%7D%5Cleft%28D_i%2C+X_i%5Cright%29%5Cright%29%5Cright%5D+.&bg=ffffff&fg=000&s=0&c=20201002)
Conclusion and discussions
In this blogpost, we introduced the setting and main results of our recent paper [JS24], that establishes the optimality of the celebrated DML algorithm, and in particular the doubly robust estimator with sample splitting, in a structure-agnostic framework for two important causal parameters: the ATE and the ATT, as well as the weighted version of the former. For practitioners, the main takeaway is that if no particular structural insights are available, then it might be better to use DML rather than more refined estimators that leverage potentially brittle assumptions on the non-parametric components of the data generating process.
[AW21] Susan Athey and Stefan Wager. Policy learning with observational data. Econometrica 89.1 (2021): 133-161.
[BKW23] Sivaraman Balakrishnan, Edward H Kennedy, and Larry Wasserman. The fundamental limits of structure-agnostic functional estimation. arXiv preprint arXiv:2305.04116, 2023.
[CCD+17] Victor Chernozhukov, Denis Chetverikov, Mert Demirer, Esther Duflo, Christian Hansen, and Whitney Newey. Double/debiased/neyman machine learning of treatment effects. American Economic Review,107(5):261–265, 2017.
[JS24] Jikai Jin and Vasilis Syrgkanis. Structure-agnostic Optimality of Doubly Robust Learning for Treatment Effect Estimation. arXiv preprint arXiv:2402.14264, 2024.
[KBRW22] Edward H Kennedy, Sivaraman Balakrishnan, James M Robins, and Larry Wasserman. Minimax rates for heterogeneous causal effect estimation. The Annals of Statistics 52.2 (2024): 793-816.
[RLM17] James M Robins, Lingling Li, and Rajarshi Mukherjee. Minimax estimation of a functional on a structured high-dimensional model. The Annals of Statistics, 45(5):1951–1987, 2017.
[RRZ94] James M Robins, Andrea Rotnitzky, and Lue Ping Zhao. “Estimation of regression coefficients when some regressors are not always observed.” Journal of the American Statistical Association 89.427 (1994): 846-866.
[LR11] M.J. Van der Laan and Sherri Rose. Targeted learning: causal inference for observational and experimental data (Vol. 4). New York: Springer.
[AP09] Joshua D. Angrist, and Jörn-Steffen Pischke. Mostly harmless econometrics: An empiricist’s companion. Princeton university press, 2009.
[CHK+24] Victor Chernozhukov, Christian Hansen, Nathan Kallus, Martin Spindler, Vasilis Syrgkanis (2024). Applied Causal Inference Powered by ML and AI.