One-Inclusion Graphs and the Optimal Sample Complexity of PAC Learning: Part 2
We’re back with the second blog post by Ishaq Aden-Ali, Yeshwanth Cherapanamjeri, Abhishek Shetty, and Nikita Zhivotovskiy, continuing on the optimal sample complexity of PAC learning. If you missed the first post, check it out here.
In the last blog post, we saw the transductive model of learning, the one-inclusion graph (OIG) algorithm and how this led to optimal in-expectation bounds for learning VC classes. But, we also saw that the OIG algorithm itself does not achieve non-trivial high probability risk bounds. In this blog post, we will see how to modify the one-inclusion graph algorithm to achieve high probability bounds. Towards this, we will see a connection to online learning and a technique known as online-to-batch.
Further, we will connect this back to the notion of exchangeability which, as we mentioned before, will play a key role.
High Probability PAC Bounds
From the previous blog post, recall that the one-inclusion graph algorithm achieved optimal results in expectation over the training data. That is, the algorithm achieved
![\mathbb{E}_{S} \left[ \Pr_{X \sim P} \left[\widehat{f}_{\mathrm{OIG}}(X) \neq f^\star(X) \right]\right] \le \frac{d}{n+1}.](https://s0.wp.com/latex.php?latex=%5Cmathbb%7BE%7D_%7BS%7D+%5Cleft%5B+%5CPr_%7BX+%5Csim+P%7D+%5Cleft%5B%5Cwidehat%7Bf%7D_%7B%5Cmathrm%7BOIG%7D%7D%28X%29+%5Cneq+f%5E%5Cstar%28X%29+%5Cright%5D%5Cright%5D++%5Cle+%5Cfrac%7Bd%7D%7Bn%2B1%7D.&bg=ffffff&fg=000&s=0&c=20201002)
It is natural to ask whether this would imply optimal results in the PAC model. That is, when we require
![\Pr_{S} \left[ \Pr_{X \sim P} \left[\widehat{f}_{\mathrm{OIG}}(X) \neq f^\star(X) \right] \geq \epsilon \right] \le \delta .](https://s0.wp.com/latex.php?latex=%5CPr_%7BS%7D+%5Cleft%5B+%5CPr_%7BX+%5Csim+P%7D+%5Cleft%5B%5Cwidehat%7Bf%7D_%7B%5Cmathrm%7BOIG%7D%7D%28X%29+%5Cneq+f%5E%5Cstar%28X%29+%5Cright%5D++%5Cgeq+%5Cepsilon+%5Cright%5D+%5Cle+%5Cdelta+.&bg=ffffff&fg=000&s=0&c=20201002)
where 
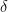

However, we will now describe a general framework that enables transferring many of these same guarantees to the PAC setting as well. The framework is a variant of the online-to-batch technique to convert strong predictors in the online setting to the batch setting of PAC learning. A key aspect of this online-to-batch conversion is that rather than building on worst case online guarantees, we will need to rely on the average performance of the online algorithm in order to get meaningful PAC guarantees.
Online-to-batch: Deterministic Error Bound
To describe the online-to-batch framework, we will use the same notation with 

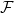






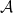

Note that key difference between the online and the PAC setting is that 



Suppose, now that we have access to a good prediction strategy for the online setting. Formally, a strategy, 

Can we now use this algorithm to derive one for the PAC setting? To see how such results transfer to the PAC setting, consider now the simpler setting where the sequence 
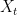
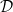





The first term above corresponds to the generalization error. Given the above decomposition, we are left with two additional issues. The first is that the above would simply bound the average risk of the 




Lemma: Let 


![\sum_{i = 1}^n W_i \leq 4 \left( \sum_{i = 1}^n \mathbb{E} [W_i \mid \mathcal{Z}_{i - 1}] + \log (2 / \delta) \right)](https://s0.wp.com/latex.php?latex=%5Csum_%7Bi+%3D+1%7D%5En+W_i+%5Cleq+4+%5Cleft%28+%5Csum_%7Bi+%3D+1%7D%5En+%5Cmathbb%7BE%7D+%5BW_i+%5Cmid+%5Cmathcal%7BZ%7D_%7Bi+-+1%7D%5D+%2B+%5Clog+%282+%2F+%5Cdelta%29+%5Cright%29&bg=ffffff&fg=000&s=0&c=20201002)
![\sum_{i = 1}^n W_i \geq \frac{1}{2}\sum_{i = 1}^n \mathbb{E} [W_i \mid \mathcal{Z}_{i - 1}] - 2 \log (2 / \delta)](https://s0.wp.com/latex.php?latex=%5Csum_%7Bi+%3D+1%7D%5En+W_i+%5Cgeq+%5Cfrac%7B1%7D%7B2%7D%5Csum_%7Bi+%3D+1%7D%5En+%5Cmathbb%7BE%7D+%5BW_i+%5Cmid+%5Cmathcal%7BZ%7D_%7Bi+-+1%7D%5D+-+2+%5Clog+%282+%2F+%5Cdelta%29&bg=ffffff&fg=000&s=0&c=20201002)
with probability at least 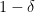
As a consequence, we get:

with probability at least 

![\mathcal{R} (\hat{f}) = \mathbb{E}_{(X, Y) \sim \mathcal{D}} [\mathbb{I} \left\{\hat{f} (X) \neq Y\right\}] \leq \frac{2}{n} \mathbb{E}_{(X, Y) \sim \mathcal{D}} \left[\sum_{i = 1}^n \mathbb{I} \left\{ f^i (X) \neq Y\right\}\right] \leq 10 \left(\frac{M + \log (1 / \delta)}{n} \right),](https://s0.wp.com/latex.php?latex=%5Cmathcal%7BR%7D+%28%5Chat%7Bf%7D%29+%3D+%5Cmathbb%7BE%7D_%7B%28X%2C+Y%29+%5Csim+%5Cmathcal%7BD%7D%7D+%5B%5Cmathbb%7BI%7D+%5Cleft%5C%7B%5Chat%7Bf%7D+%28X%29+%5Cneq+Y%5Cright%5C%7D%5D+%5Cleq+%5Cfrac%7B2%7D%7Bn%7D+%5Cmathbb%7BE%7D_%7B%28X%2C+Y%29+%5Csim+%5Cmathcal%7BD%7D%7D+%5Cleft%5B%5Csum_%7Bi+%3D+1%7D%5En+%5Cmathbb%7BI%7D+%5Cleft%5C%7B+f%5Ei+%28X%29+%5Cneq+Y%5Cright%5C%7D%5Cright%5D+%5Cleq+10+%5Cleft%28%5Cfrac%7BM+%2B+%5Clog+%281+%2F+%5Cdelta%29%7D%7Bn%7D+%5Cright%29%2C&bg=ffffff&fg=000&s=0&c=20201002)
as the majority classifier 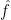
Even for simple hypothesis classes, such linear thresholds in one dimension any online prediction strategy for the simplest setting of threshold classifiers must incur error 
Online-to-batch: PAC Error Bound
Given the worst-case error guarantees of an online learning algorithm, it is natural to conclude that the online-to-batch framework cannot yield non-trivial conclusions for the PAC setting. However, a more careful analysis of the argument from the previous section shows we only require an online learning algorithm that performs well on sequences generated i.i.d. from a distribution. One might think that one immediately needs to worry about “average-case” instances that come from a distribution and this would potentially lead to a PAC guarantee. But it turns out in most cases, the choice of the instances 


with high probability over the choice of 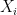
![\mathbb{E}[\mathbb{I} \left\{Y_i \neq f^{i - 1} (X_i) \right\} | (X_1, Y_1),\dots, (X_{i-1} , Y_{i-1}) ]](https://s0.wp.com/latex.php?latex=%5Cmathbb%7BE%7D%5B%5Cmathbb%7BI%7D+%5Cleft%5C%7BY_i+%5Cneq+f%5E%7Bi+-+1%7D+%28X_i%29+%5Cright%5C%7D+%7C+%28X_1%2C+Y_1%29%2C%5Cdots%2C+%28X_%7Bi-1%7D+%2C+Y_%7Bi-1%7D%29+%5D&bg=ffffff&fg=000&s=0&c=20201002)
in terms of the VC dimension. Note that in this argument, we would need to condition on 
But, let us try to recall what type of guarantees we have already seen from transductive learning. Note that the one can interpret the OIG as an algorithm
![\frac{1}{i!} \sum_{ \pi } \mathbb{I} \left[ Y_{\pi(i)} \neq \mathcal{A} ( X_{ \pi(i) } ; \{ (X_{ \pi( k) } , Y_{\pi(k)} ) \}_{ \pi(k) \neq \pi(i) } ) \right] \leq \frac{d}{i}](https://s0.wp.com/latex.php?latex=%5Cfrac%7B1%7D%7Bi%21%7D+%5Csum_%7B+%5Cpi+%7D+%5Cmathbb%7BI%7D+%5Cleft%5B+Y_%7B%5Cpi%28i%29%7D+%5Cneq+%5Cmathcal%7BA%7D+%28+X_%7B+%5Cpi%28i%29+%7D+%3B+%5C%7B+%28X_%7B+%5Cpi%28+k%29+%7D+%2C+Y_%7B%5Cpi%28k%29%7D+%29+%5C%7D_%7B+%5Cpi%28k%29+%5Cneq+%5Cpi%28i%29+%7D+%29+%5Cright%5D+%5Cleq+%5Cfrac%7Bd%7D%7Bi%7D&bg=ffffff&fg=000&s=0&c=20201002)
The sum is over all permutations. But, this seems to be insufficient for what we need since naively to apply the martingale argument, we don’t get to average over the choice of test point again.
But, the above way of thinking of problem is still useful. The first high level point is that, in order to evaluate the loss and use the average case nature of the instances, ideally we would like to condition on as little as possible. This would allow for us preserve more randomness in order to use the average case nature of the problem. So, what should be condition on?
The first observation is a key aspect that mathematically characterizes why i.i.d. sequences are unlikely to behave like worst-case ones. This is the notion of exchangeability i.e. that i.i.d. sequences are equivalent to be presented in random order. Recall that a sequence of random variables 



We have observed that for ![\mathbb{I} [ Y_j \neq A(X_j ; \{ (X_1, Y_1) , \dots (X_{j-1} , Y_{j-1} ) ) ]](https://s0.wp.com/latex.php?latex=%5Cmathbb%7BI%7D+%5B+Y_j+%5Cneq+A%28X_j+%3B+%5C%7B+%28X_1%2C+Y_1%29+%2C+%5Cdots+%28X_%7Bj-1%7D+%2C+Y_%7Bj-1%7D+%29+%29+%5D+&bg=ffffff&fg=000&s=0&c=20201002)


To formalize this notion, we introduce some notation that clarifies the conditioning in our argument. Let

The random quantity 



This would happen if
We could now apply martingale arguments to ![\mathbb{E} \left[W_{i - 1} \mid \mathcal{Z}_i \right]](https://s0.wp.com/latex.php?latex=%5Cmathbb%7BE%7D+%5Cleft%5BW_%7Bi+-+1%7D+%5Cmid+%5Cmathcal%7BZ%7D_i+%5Cright%5D&bg=ffffff&fg=000&s=0&c=20201002)
![\mathbb{E} \left[ W_{i - 1} \mid \mathcal{Z}_i \right] \leq M_i](https://s0.wp.com/latex.php?latex=%5Cmathbb%7BE%7D+%5Cleft%5B+W_%7Bi+-+1%7D+%5Cmid+%5Cmathcal%7BZ%7D_i+%5Cright%5D+%5Cleq+M_i&bg=ffffff&fg=000&s=0&c=20201002)
where 

This is due to the fact that conditioned on 


![\mathbb{E} \left[ W_{i - 1} \mid \mathcal{Z}_i \right] \leq \frac{d}{i}.](https://s0.wp.com/latex.php?latex=%5Cmathbb%7BE%7D+%5Cleft%5B+W_%7Bi+-+1%7D+%5Cmid+%5Cmathcal%7BZ%7D_i+%5Cright%5D+%5Cleq+%5Cfrac%7Bd%7D%7Bi%7D.&bg=ffffff&fg=000&s=0&c=20201002)
Furthermore, since each 

with probability at least
One final trick that we need to fix this issue is considering 


Hence, by simply exploiting the permutation-invariance of the distribution generating the input sequence, we are able to obtain a high-probability concentration inequality for the mistake bound that is substantially better than the worst-case bound incurred for arbitrary realizable input sequences. This mistake bound along with the discussion in the previous section now yields PAC learners with optimal high-probability guarantees.
Theorem 3 [Optimal Sample Complexity of PAC Learning, [AACSZ23a]] Let 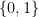



Let 



![\Pr_{x \sim D } \left[ \hat{f}(x) \neq f^{\star}(x) \right] \leq \epsilon.](https://s0.wp.com/latex.php?latex=%5CPr_%7Bx+%5Csim+D+%7D+%5Cleft%5B+%5Chat%7Bf%7D%28x%29+%5Cneq+f%5E%7B%5Cstar%7D%28x%29+%5Cright%5D+%5Cleq+%5Cepsilon.+&bg=ffffff&fg=000&s=0&c=20201002)
Conclusions
In this pair of blogposts, we discussed the problem binary classification in both the PAC and transductive models of learning. We talked about an elegant learning algorithm in the transductive learning model based on the idea of one-inclusion graphs. We then saw how the classic notion of online-to-batch conversion can be modified in a simple way in order to port strong learning guarantees from the transductive model to the PAC model in an optimal way. Though the focus of this blogpost was on binary classification, the ideas we discussed naturally extend to other settings such as multiclass classification and regression and thus these techniques can be seen as a unifying perspective on optimal PAC bounds in various models of realizable learning. For more details on this, check out the full paper [AACSZ23a] (and maybe also [AACSZ23b]).
An interesting direction for future study is whether the techniques presented here could lead to proofs of optimal PAC bounds in the agnostic setting, where all known such bounds go through so-called chaining techniques. It would be interesting to develop techniques that unify approaches to obtaining optimal PAC bounds in both the realizable and agnostic cases.
References
- [Lit89] Nick Littlestone: From on-line to batch learning. In Proceedings of the Second Annual Workshop
on Computational Learning Theory, pages 269–284. Morgan Kaufmann, 1989. - [AACSZ23a] Ishaq Aden-Ali, Yeshwanth Cherapanamjeri, Abhishek Shetty, and Nikita Zhivotovskiy. Optimal PAC bounds without uniform convergence, In Foundations of Computer Science (FOCS), 2023.
- [AACSZ23b] Ishaq Aden-Ali, Yeshwanth Cherapanamjeri, Abhishek Shetty, and Nikita Zhivotovskiy. The one-inclusion graph algorithm is not always optimal. In Conference on Learning Theory (COLT), 2023.
- The argument presented here is slightly simpler. In his original argument, Littlestone used a small holdout set to pick the best hypothesis in the sequence instead of taking a majority vote. ↩︎
- The notion of complexity, analogous to the VC dimension, that captures this setting is known as the Littlestone dimension. It turns out that even for simple classes such as the set of thresholds, this complexity is unbounded. ↩︎